Sieci neuronowe typu Transformer (Transformator) zyskują w ostatnim czasie bardzo na popularności. Zostały zaprojektowane w celu przetwarzania danych sekwencyjnych – transformują pewne sekwencje wejściowe na wyjściowe. Do zadań sekwencyjnych można zaliczyć różne zadania NLP (przetwarzania języka naturalnego), rozpoznawanie mowy (mowa jest zamieniana na jej transkrypcję; na wejściu sieć otrzymuje sekwencję w postaci kolejnych próbek rozpoznawanego dźwięku, a na wyjściu generuje sekwencję kolejnych słów rozpoznanej mowy), generowanie mowy (operacja odwrotna do opisanej powyżej), tłumaczenie tekstów itd.
Aby można było skuteczne przetwarzać dane sekwencyjne, potrzebna jest pamięć, która pozwoli modelowi znajdować różnego rodzaju zależności pomiędzy danymi. Przykładowo podczas tłumaczenia zdań w języku polskim na język angielski:
Alan Turing (ur. 23 czerwca 1912 w Londynie, zm. 7 czerwca 1954 w Wilmslow k. Manchesteru) – brytyjski matematyk, kryptolog, twórca koncepcji maszyny Turinga i jeden z twórców informatyki. Uważany za ojca sztucznej inteligencji.
powinniśmy uwzględniać kontekst aktualnie tłumaczonego fragmentu. Drugie zdanie zaczynające się od „Uważany” odnosi się do Alana Turinga opisywanego w pierwszym zdaniu. Sieć powinna dostrzec tę zależność, ponieważ takie relacje są bardzo istotne w procesie tłumaczenia. Do tego potrzebna jest pamięć wcześniejszych słów.
W takich zadaniach popularnym wyborem są rekurencyjne sieci neuronowe (RNN) i splotowe sieci neuronowe (CNN), które mogą być do tego celu odpowiednio przystosowane. W dalszej części artykułu opiszę ich działanie, po czym przejdziemy do wyjaśnienia działania Transformatorów, które rozwiązują problemy występujące z sieciami RNN i CNN.
Sieci RNN
Rekurencyjne sieci neuronowe posiadają w sobie pętle, co pozwala im przechowywać informacje:
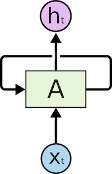
Na powyższym rysunku widzimy część A sieci neuronowej, która przetwarza pewne informacje wejściowe znajdujące się na Xt i produkuje sygnały wyjściowe ht. Pętla pozwala na przekazanie informacji pomiędzy poszczególnymi krokami przetwarzania. Rekurencyjną sieć neuronową możemy traktować jako wielokrotne kopie A, z których każda przekazuje wiadomość następcy. „Rozwiniętą” pętlę sieci rekurencyjnej możemy przedstawić następująco:
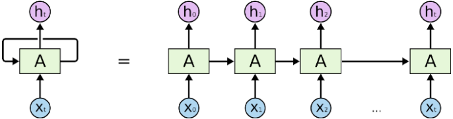
Ze względu na łańcuchową naturę, rekurencyjne sieci neuronowe znakomicie nadają się do przetwarzania danych sekwencyjnych. Jeśli chcielibyśmy przetłumaczyć tekst, każde słowo zdania tłumaczonego mogłoby trafić do osobnego wejścia. Później, w procesie przetwarzania informacji, RNN przekazuje informacje o poprzednich słowach do kolejnych części sieci, które będą mogły z nich skorzystać i odpowiednio przetworzyć.
Modele zamieniające pewną sekwencję wejściową w jednej domenie na sekwencję wyjściową w innej domenie są nazywane SEQ2SEQ . Najprostszy model SEQ2SEQ składa się z 2 komponentów – enkodera i dekodera RNN.
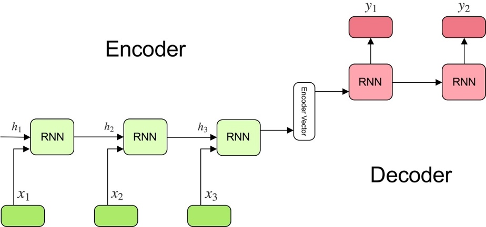
Schemat działania SEQ2SEQ jest następujący:
– Zadaniem enkodera wejściowego (złożonego z warstwy powtarzających się jednostek, np. RNN) jest utworzenie wewnętrznej reprezentacji wektorowej tekstu wejściowego. Owy stan wewnętrzny enkodera będzie służył do warunkowania dekodera. Każda jednostka RNN otrzymuje informacje o pojedynczym elemencie, przetwarza informacje i przekazuje je dalej. Załóżmy, że na wejściu zadajemy tekst do przetłumaczenia. Sekwencja wejściowa jest zbiorem wszystkich słów zawartych w tym tekście. Każde słowo jest reprezentowane jako x_i, gdzie i to pozycja tego słowa w zdaniu wejściowym. Ukryte stany h_i mogą być obliczone z użyciem formuły: h_t=f(W^hh 〖h_t〗_(-1)+W^hx x_t), która reprezentuje wynik działania zwykłej rekurencyjnej sieci neuronowej w kolejnych krokach czasowych t.
– Dekoder (zbiór powtarzających się jednostek, np. RNN, z których każda przewiduje wynik y_t w kroku czasowym t), otrzymawszy ową sekwencję, generuje tekst wyjściowy z tłumaczeniem. Jest w ten sposób warunkowany kontekstem na wyjściu enkodera. Dekoder jest uczony przewidywania następnych znaków sekwencji docelowej, biorąc pod uwagę poprzednie znaki sekwencji i generuje słowa, dopóki nie zostanie utworzony specjalny znacznik końca zdania.
W problemie tłumaczenia, sekwencja wyjściowa będzie zbiorem słów, z których składa się przetłumaczone zdanie. Każde słowo jest reprezentowane jako y_i, gdzie i oznacza kolejność słowa w zdaniu. Każdy ze stanów wewnętrznych h_i jednostek RNN dekodera może być wyliczony przy pomocy formuły: h_t=f(W^hh h_(t-1) ). Sygnał wyjściowy y_t w kroku czasowym t, może być obliczony w sposób następujący: h_t=softmax(W^S h_t ). Wyjścia obliczamy wykorzystując stan ukryty w bieżącym kroku czasowym wraz z odpowiednią wagą W(S). Funkcja softmax służy do stworzenia wektora prawdopodobieństwa, który pomoże określić ostateczny wynik (słowo w sekwencji wyjściowej).
Istnieje wiele modeli SEQ2SEQ – np. powstałych z użyciem sieci RNN, LSTM, GRU lub konwolucyjnych 1D. Zaprezentowany powyżej schemat dotyczy najprostszego modelu sekwencyjnego. W bardziej skomplikowanych wykorzystuje się np. większą liczbę wektorów do kodowania sekwencji wejściowej, co pozwala uchwycić więcej istotnych w przetwarzaniu tekstu informacji.
Problem z długoterminowymi zależnościami
Załóżmy, że tworzymy model językowy, którego zadaniem jest przewidywanie kolejnych słów na podstawie poprzednich. Jeśli staramy się przewidzieć następne słowo w zdaniu „chmury są na…”, nie potrzebujemy dalszego kontekstu, bowiem łatwo zgadnąć, że następnym słowem będzie „niebie”. W tym przypadku doskonale sprawdzą się sieci RNN – nie jest potrzebna szczegółowa analiza kontekstu w tekście. Są jednak sytuacje, w których jest on potrzebny…
„Dorastałem w Polsce. Moim ojczystym językiem jest…”
Ostatnia informacja sugeruje, że następnym słowem jest zapewne jakiś język, jednak aby dowiedzieć się jaki dokładnie, potrzebujemy kontekstu Polska z pierwszego zdania. Sieci RNN nie są niestety zbyt skuteczne, jeśli odległość pomiędzy wymaganymi informacjami dot. kontekstu a miejscem, w których ich potrzebujemy, jest duża. Wynika to z faktu, że informacja jest przekazywana w każdym kroku przetwarzania i im dłuższy jest łańcuch, tym jest większe prawdopodobieństwo, że zostanie utracona. Teoretycznie sieci RNN mogłyby się nauczyć takich długoterminowych zależności, w praktyce jednak się nie uczą. Dlatego powstały sieci LSTM, które starają się rozwiązać ten problem.
Sieci LSTM – specjalny rodzaj RNN
Gdy układamy swój kalendarz na dany dzień, ustalamy priorytety spotkań. Jeśli mamy coś ważnego, to możemy część mniej istotnych spotkań odwołać lub przełożyć, wybierając to, co jest naprawdę ważne.
Sieci RNN tego niestety nie robią, a cała informacja podlega modyfikacji. Sieć nie bierze pod uwagę tego, co jest ważne, a co nie. Pewnym rozwiązaniem tego problemu są sieci LSTM, gdzie informacje przepływają przez mechanizm zwany stanem komórek, przez co sieć może wybiórczo pamiętać rzeczy istotne, a zapominać mniej.
Sieć LSTM wygląda następująco:
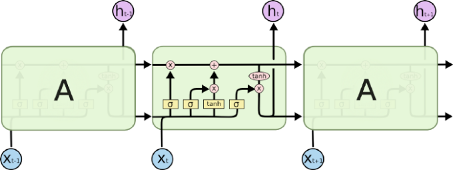
Każda komórka bierze na wejściu sygnał Xt (w problemie tłumaczenia tekstu będą to kolejne słowa do przetłumaczenia), a także uwzględnia wcześniejszy stan komórki oraz sygnał na wyjściu z poprzedniej komórki. Manipuluje następnie tymi informacjami wejściowymi i generuje nowy stan komórki i sygnał wyjściowy.
Problem z LSTM jest taki, że zbyt długie zdania nie są poprawnie przetwarzane – podobnie jak w przypadku RNN. Powodem tego jest to, że prawdopodobieństwo zachowania kontekstu ze słowa, które jest daleko od aktualnie przetwarzanego, maleje wykładniczo wraz z odległością od niego. Gdy zdania są zbyt długie, to model często zapomina treści z odległych pozycji w sekwencji. Innym problemem związanym z LSTM i RNN jest to, że trudno jest zrównoleglić pracę nad przetwarzaniem zdań, ponieważ należy przetwarzać słowo po słowie.
Mechanizm uwagi
Aby rozwiązać opisywane wcześniej problemy, naukowcy zaprezentowali metodę zwaną mechanizmem uwagi, który pozwala zwrócić uwagę na specyficzne słowa w tekście. Czytając ten tekst, zawsze koncentrujesz się na czytanym słowie, ale jednocześnie twój umysł wciąż trzyma w pamięci ważne słowa kluczowe tekstu, aby zapewnić kontekst. Sztuczne sieci neuronowe mogą osiągnąć to samo z użyciem mechanizmu attention, skupiając się na części podzbioru otrzymywanych informacji.
Rozważmy przykład z RNN – zamiast kodować całe zdanie w stanie ukrytym, każde słowo ma odpowiadający mu stan ukryty, który jest przekazywany do etapu dekodowania. Idea polega na tym, że każde słowo może zawierać istotne informacje. Dlatego nie kodujemy już całego zdania wejściowego w enkoderze do wektora cech, co może pogorszyć skuteczność konwersji przy dłuższych sekwencjach, gdzie występuje wiele różnych zależności pomiędzy słowami (wadą tego rozwiązania jest to, że dekoder generuje sekwencję wyjściową tylko na podstawie ostatniego stanu ukrytego – ostatniej jednostki enkodera). Zamiast tego, pozwalamy dekoderowi przetwarzać różne części zdania wejściowego podczas generowania sekwencji wyjściowej – każde słowo wyjściowe zależy bowiem od ważonej kombinacji wszystkich stanów wejściowych, a nie tylko od stanu ostatniego, co pokazuje poniższy rysunek. Co ważne, pozwalamy modelowi nauczyć się, na co zwracać uwagę na podstawie zdania wejściowego i tego, co w danym kroku czasowym wyprodukował.
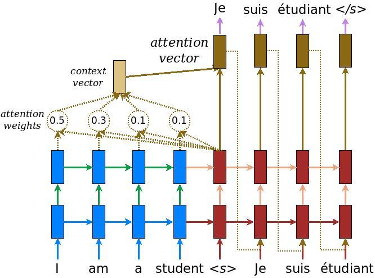
Po dodaniu mechanizmu uwagi wyniki ulegają poprawie, jednak niektóre z problemów, o których pisałem, nadal nie są rozwiązywane. Na przykład równoległe przetwarzanie danych wejściowych nie jest możliwe. W przypadku dużej ilości tekstu zwiększa to czas przetwarzania danych.
Sieci CNN
Sieci CNN (splotowe sieci neuronowe) mogą pomóc w rozwiązaniu problemu z brakiem równoległego przetwarzania danych. Ten rodzaj sieci jest coraz częściej stosowany – niektóre z najpopularniejszych sieci neuronowych do przetwarzania sekwencji to konwolucyjne sieci neuronowe – np. Wavenet (rysunek poniżej) i Bytenet.
Powodem, dla którego konwolucyjne sieci neuronowe mogą działać równolegle jest brak rekurencji – że każde słowo na wejściu może być przetwarzane w tym samym czasie i niekoniecznie zależy od poprzednich słów. „Odległość” pomiędzy słowem wyjściowym a dowolnym wejściem dla CNN jest rzędu log (N) – to jest wielkość wysokości drzewa generowanego od wyjścia do wejścia. Jest to znacznie optymalniejsze niż w przypadku RNN, gdzie odległość jest rzędu N.
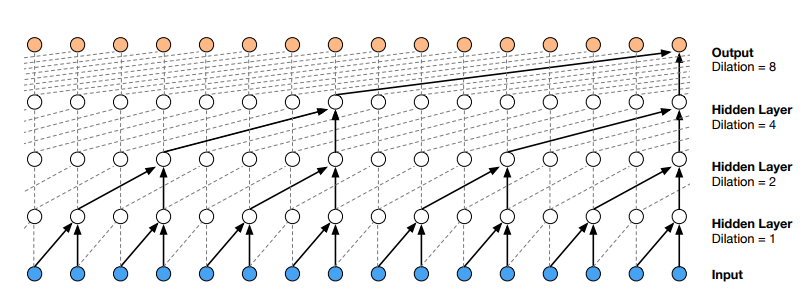
Problem w tym, że konwolucyjne sieci neuronowe niekoniecznie pomagają w rozwiązywaniu problemu zależności pomiędzy wyrazami podczas np. tłumaczenia zdań. Dlatego powstały Transformatory, które są połączeniem CNN z mechanizmem uwagi.
Transformers (Transformatory)
Aby doprowadzić do zrównoleglenia obliczeń, Transformery próbują rozwiązać problem za pomocą konwolucyjnych sieci neuronowych wraz z mechanizmem uwagi (attention). Attention zwiększa szybkość, z jaką model może przejść z jednej sekwencji do drugiej. Tę architekturę sieci neuronowej zaprezentowano w publikacji „Attention Is All You Need”.
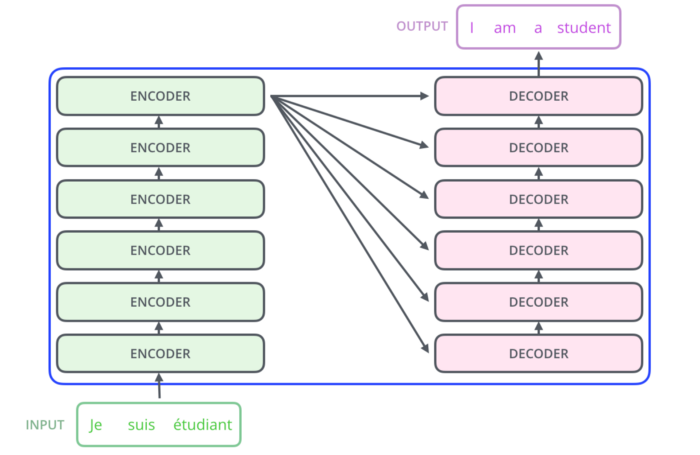
Przyjrzyjmy się, jak działa Transformer. To model, który wykorzystuje mechanizm uwagi attention, a mówiąc dokładniej – self-attention. Wewnętrznie Transformera ma podobną architekturę do modeli powyżej, ale składa się z sześciu koderów i sześciu dekoderów:
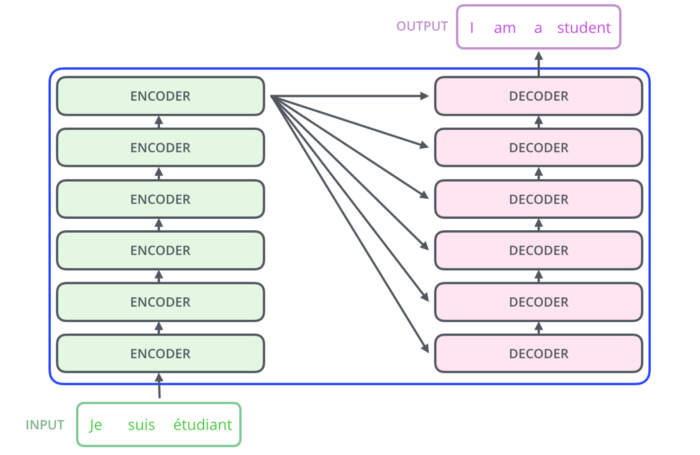
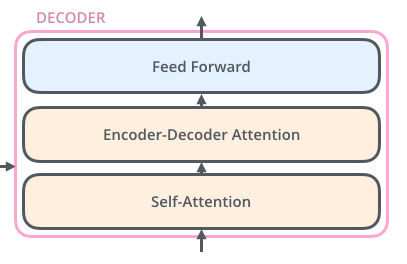
Każdy enkoder jest do siebie bardzo podobny – posiada tę samą architekturę co pozostałe. Dekodery są również do siebie bardzo podobne i posiadają te same właściwości. Każdy enkoder składa się z dwóch warstw: self-attention i sieci neuronowej typu Feed Forward.
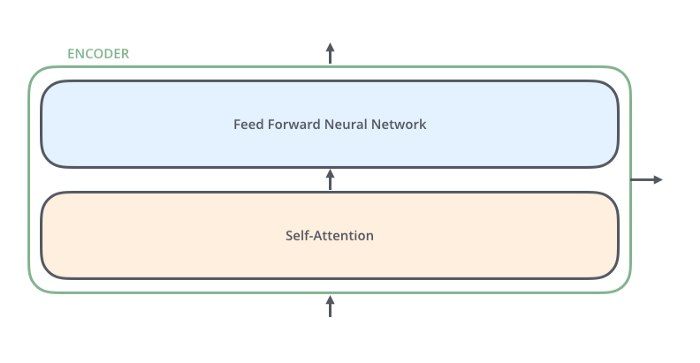
Dane wejściowe kodera najpierw przepływają przez warstwę self-attention. Pomaga to enkoderowi, gdy koduje określone słowo, spojrzeć również na inne słowa w zdaniu wejściowym. Dekoder ma obie te warstwy, ale między nimi znajduje się warstwa attention, która pomaga dekoderowi skupić się na odpowiednich częściach zdania wejściowego.
Ciąg dalszy artykułu nastąpi…
Na podstawie:
https://medium.com/inside-machine-learning/what-is-a-transformer-d07dd1fbec04
https://towardsdatascience.com/transformers-141e32e69591
https://arxiv.org/abs/1706.03762
https://lionbridge.ai/articles/what-are-transformer-models-in-machine-learning/