Robot społeczny jako interfejs człowiek - maszyna. Wykorzystanie metod NLP do naturanej komunikacji w języku polskim

Model antropomorficznego robota społecznego - nowego jakościowo rodzaju interfejsu człowiek-komputer. Robot jest fizycznym awatarem dla programu bota i autorskiego syntezatora naturalnej mowy, czyli głównych komponentów systemu. Połączenie komponentów robota z chatbotem i systemem syntezy mowy sprawia, że awatar słyszy to, o co go pytamy i odpowiada w języku polskim, IMITUJĄC barwę głosu i sposób mówienia wybranej osoby. Zamontowana w robocie kamera pozwala na rozpoznawanie przedmiotów w otoczeniu. Robot jest przyczynkiem kolejnej generacji robotów społecznych, nad którymi pracuję. Popiersie robota może zostać wykorzystane w miejscach i sytuacjach, gdzie jest potrzebny kontakt z drugim człowiekiem - w muzeach, galeriach, centrach wystawienniczych, restauracjach... Jeśli chciałbyś wykorzystać takiego robota w np. celach reklamowych - zapraszam do kontaktu! Możliwe jest zbudowanie robota odwzorowującego dowolną postać i przygotowanego do rozmowy na dowolne tematy, co można wykorzystać do kontaktu z klientami.
Roboty coraz częściej towarzyszą nam w naszym życiu. Koncepcja stworzenia czegoś na obraz i podobieństwo człowieka nie jest nowa. Już w starożytnej Grecji powstawały mity, np. o Talosie (Τάλως) – olbrzymie z brązu, strzegącym Krety. Celem mojej pracy było stworzenie robota - fizycznego awatara, ułatwiającego komunikację komputera z człowiekiem i vice versa. Po wgraniu mindfiles (w postaci wcześniej wygenerowanej bazy wiedzy) awatar może reprezentować nasz behawior w przyszłości, dzięki czemu np. nasi wnukowie zobaczą to, jacy byliśmy w przeszłości.
Konstrukcja mechaniczna jest połączeniem elementów metalowych i plastikowych, w tym wydrukowanych przy pomocy drukarki 3D. Czaszkę powleczono silikonowym odlewem głowy, który jest wprawiany w ruch przez epoksydowe elementy, połączone mechanicznie (przy pomocy m.in. linek) z serwomechanizmami. Ich sterowaniem zajmuje się system wbudowany oparty na mikrokontrolerach AVR. Owy układ połączono z komputerem, gdzie mieści się aplikacja przetwarzająca sygnały pochodzące z robota, generująca sekwencje ruchowe awatara i komunikująca się z chmurą obliczeniową w celu syntezy personalizowanej mowy.
Podstawą konstrukcji mechanicznej jest metalowy trzon, który mocuje głowę do plastikowej podstawy. Jest on osadzony w przegubie kulowym, umożliwiającym obrót szyi w trzech osiach. Sterowanie szyją (pozycją przegubu) jest realizowane przez 2 silniki komutatorowe, współpracujące z zębatą przekładnią walcową o zębach prostych, która służy do przeniesienia napędu, zwiększenia momentu siły oraz poruszania listwą zębatą.
Czaszka robota została wyposażona w następujące serwomechanizmy:
- szczęki,
- ruchu oczu w górę / dół,
- ruchu gałek ocznych w lewo / prawo,
- dwa serwomechanizmy powiek,
- brwi.
Pozostałe serwomechanizmy, które ruszają:
- górną częścią ust,
- lewą częścią ust,
- prawą częścią ust,
- brwią lewą,
- brwią prawą
zamontowano do postawy robota, a siła jest przekazywana przy pomocy linek, przyklejonych, od strony głowy, do epoksydowych podkładek.
Sterownik serwomechanizmów oraz centralny system wbudowany, znajdujący się w obudowie robota, oparto na 8-bitowych mikrokontrolerach AVR. Taktowane są zewnętrznym rezonatorem kwarcowym o częstotliwości podstawowej wynoszącej 8MHz. W układzie elektronicznym znajduje się również część analogowa, która odpowiada za m.in. wzmacnianie sygnału audio z DAC (mowa robota), filtrację sygnału AUDIO i kontrolę napięcia zasilania (przetwornice impulsowe, układy filtrujące...).

W projekcie wykorzystano następujące rodzaje serwomechanizmów:
- szczęka (x1): serwo analogowe TowerPro MG-946R, moment: 13 kg*cm, prędkość: 0,17s/60,
- oczy góra / dół (x1): serwo cyfrowe TowerPro MG-90D - micro, moment: 2,4 kg*cm (0,23 Nm), prędkość: 0,08 s/60°,
- gałki oczne lewo / prawo (x1): serwo cyfrowe TowerPro MG-90D - micro, moment: 2,4 kg*cm (0,23 Nm), prędkość: 0,08 s/60°,
- powieki (x2): serwo cyfrowe TowerPro MG-90D - micro, moment: 2,4 kg*cm (0,23 Nm), prędkość: 0,08 s/60°,
- brwi (x2): serwo analogowe Feetech FR5311M, moment: 14,5 kg*cm (1,45 Nm), Prędkość: 0,13 s/60°,
- górna część ust (x1): serwo cyfrowe PowerHD HD-8307TG - gigant, moment: 8,5 kg*cm (0,84 Nm), prędkość: 0,08 s/60°,
- lewa i prawa część ust (x4): serwo analogowe TowerPro MG-946R, moment: 13 kg*cm, prędkość: 0,17s/60,
- lewa i prawa brew (x2): serwo analogowe TowerPro MG-946R, moment: 13 kg*cm, prędkość: 0,17s/60,
- ramiona (x2): serwo cyfrowe Feetech Wing FT3325M - micro, moment: 7,21 kg*cm (0,71 Nm), prędkość: 0,13 s/60°.
oraz silniki komutatorowe do sterowania szyją.

Odlew głowy i silikonową maskę zaprezentowano na poniższym rysunku. Maska jest negatywem modelu głowy, wykonanego z masy formierskiej. Czaszka z podstawą, na której osadzono maskę, stanowi kombinację własnych komponentów wydrukowanych przy pomocy drukarki 3D lub odlanych w żywicy epoksydowej i fabrycznych części pochodzących z posiadanych przez autora lalek i zabawek.

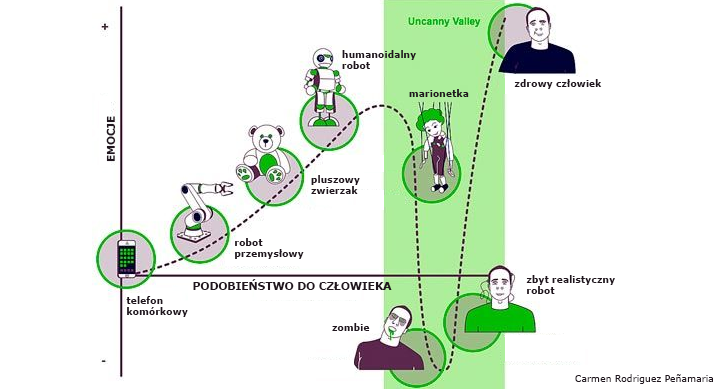
Badania pokazują, że komfort psychiczny obserwatora konwersującego z robotem jest zależny od stopnia podobieństwa robota do człowieka, co zaprezentowano na poniższym rysunku. Ta hipoteza nazywa się doliną niesamowitości i zakłada, że im robot jest bardziej podobny do człowieka, tym wydaje się sympatyczniejszy. Dzieje się tak jednak tylko do pewnego momentu, w którym następuje gwałtowny spadek komfortu psychicznego obserwatora. Po przekroczeniu kolejnego punktu na wykresie komfort psychiczny ponownie rośnie – wtedy robot staje się nieodróżnialny od człowieka. Starałem się mieć to na uwadze podczas projektowania systemu.
Do informowania użytkownika o stanie emocjonalnym robota wykorzystano cyfrowy, adresowany pasek LED RGB WS2813, podłączony do modułu sterującego serwomechanizmami.
Program pracujący na PC został napisany w języku JAVA, w środowisku NetBeans. Posłużono się narzędziem Apache Maven, automatyzującym budowę oprogramowania. Zadaniem aplikacji jest:
- wysyłanie modułom w robocie sekwencji sterujących serwomechanizmami,
- przetwarzanie danych z kamery i rozpoznawanie obiektów w otoczeniu,
- komunikacja z chmurą obliczeniową Google Cloud w celu: rozpoznawania mowy (STT) i generowania mowy (własny TTS, opisany w zakładce Projekty),
- odpowiadanie na zadane robotowi pytania – zaimplementowano chatbota (AIML + model SEQ2SEQ oparty na rekurencyjnych sieciach neuronowych z analizą składowej emocjonalnej wypowiedzi).
Do komunikacji aplikacji z chmurą obliczeniową (instancja maszyny wirtualnej w Google Cloud; dysk twardy 100GB, RAM 60GB, 2 karty graficzne NVIDIA Tesla K80) zostało wykorzystane REST API.
Detekcję i rozpoznawanie twarzy oparto na bibliotece OpenCV. Biblioteka OpenCV jest zbiorem funkcji programistycznych wykorzystywanych w czasie wykonywania operacji na obrazach. Została oparta na otwartym kodzie, a jej cechą jest dostępność na wielu platformach. Bibliotekę stworzono w języku C, jednak istnieje implementacja dla m.in. Javy, co wykorzystano w tym systemie. Do detekcji twarzy na zdjęciu biblioteka korzysta z klasyfikatora kaskadowego Haar, a do rozpoznawania z algorytmu histogramów lokalnych, binarnych wzorców LBPH (Local Binary Patterns Histograms).
Jedną z głównych funkcjonalności systemu jest rozpoznawanie rodzaju obiektów innych niż twarz, które znajdują się w otoczeniu. Dzięki temu robot może orientować się w środowisku i je komentować. Służą do tego głębokie sieci neuronowe, które stworzono z wykorzystaniem biblioteki Tensorflow i MXNet, pozwalającej na projektowanie, uczenie i implementowanie głębokich sieci neuronowych w szerokiej gamie platform – od systemów chmurowych do urządzeń mobilnych. Zapewnia wysoki stopień skalowalności i szybsze uczenie modeli neuronowych. Korzystając z biblioteki, utworzono głęboką sieć neuronową, którą uczono z wykorzystaniem zbioru uczącego wydzielonego z bazy ImageNet. Liczba klas w zbiorze uczącym wynosi 1000 – znajdują się w nim podstawowe obiekty, które spotyka osoba niewidoma na co dzień. Uczenie przeprowadzono na klastrze obliczeniowym wyposażonym w karty GTX 980. Skuteczność klasyfikacji wytrenowanego modelu wynosi 78% dla danych ze zbioru walidacyjnego, który powstał poprzez losowe wydzielenie ok. 20% zbioru uczącego.
W systemie pracują dwa chatboty. Pierwszy z nich posługuje się bazą wiedzy, zawierającą słowa kluczowe przypisane do wcześniej zdefiniowanych odpowiedzi. Do tworzenia bazy wiedzy został wykorzystany język znaczników AIML. W systemie wykorzystano również chatbota, opierającego się na rekurencyjnych sztucznych sieciach neuronowych. Chatbot SEQ2SEQ składa się z 2 komponentów – kodera i dekodera RNN, co opisano w artykule dotyczącym chatbota w zakładce Projekty.
System syntezy mowy nie korzysta ze standardowego syntezatora mowy typu Ivona. Autor dążył do tego, aby syntezowany głos był jak najbardziej naturalny i przypominał swoim brzmieniem głos wybranej osoby. W przykładzie starano się odwzorować brzmienie głosu autora tej pracy. System bazuje na nowatorskiej technice syntezy mowy opartej na bazie głębokich splotowych sieci neuronowych (CNN), zajmujących się przetwarzaniem sekwencyjnych danych, jakimi jest mowa. W celu wyszkolenia zbudowanej splotowej sieci neuronowych, przygotowano ciąg uczący składający się z 20 godzin nagrań głosu i odpowiadającej transkrypcji czytanych słów.
Na poniższym rysunku zaprezentowano schemat blokowy prezentowanego systemu.
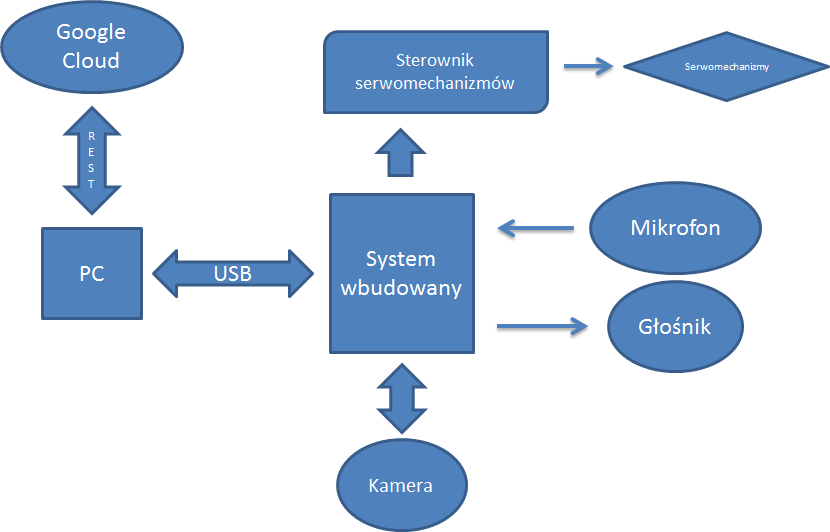
Wykorzystane technologie: DCN, LSTM, Haar, MXNet, OpenCV, Tensorflow, Google Cloud, STM32, AVR...